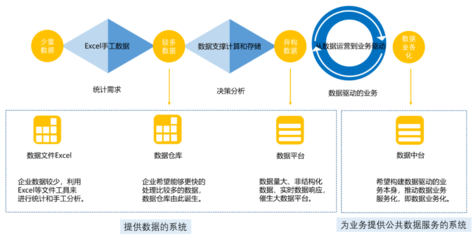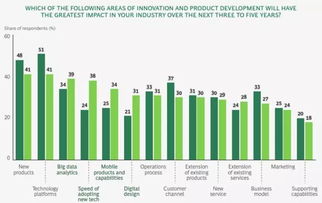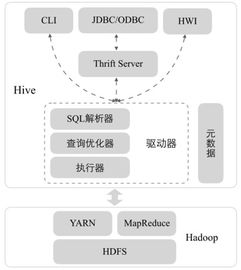
在数字化转型的浪潮中,微服务架构因其灵活性、可扩展性和独立部署能力,已成为构建复杂企业应用的主流选择。随着业务系统被拆分为众多独立、自治的微服务,数据也相应地分散在各个服务的私有数据库中。如何从这些分布式的数据源中高效、准确地进行数据抽取,并完成跨服务的统计与分析,成为微服务场景下数据处理面临的核心挑战。本文将探讨在微服务环境中构建数据抽取与统计服务的关键策略、技术选型与最佳实践。
一、微服务数据处理的独特挑战
与传统单体应用集中式数据库不同,微服务架构强调“数据库私有化原则”,即每个服务拥有并管理自己的数据存储,数据所有权清晰,服务间通过API进行通信。这种模式带来了去中心化的数据管理,但也引入了数据整合的难题:
- 数据孤岛:关键业务数据被隔离在不同的服务边界内,缺乏全局视图。
- 一致性挑战:跨服务的事务难以保证强一致性,基于最终一致性的数据可能在不同时间点存在差异。
- 性能瓶颈:频繁的跨服务API调用(如JOIN操作)以获取关联数据,会严重影响查询性能和系统可用性。
- 技术异构性:不同服务可能采用不同类型的数据库(SQL、NoSQL),增加了数据格式统一与转换的复杂度。
二、数据抽取策略:从分散到集中
为了支撑跨域的统计、分析与报表需求,必须将分散的数据以适当的方式“抽取”并整合。主要有以下几种策略:
1. API聚合层(BFF - Backend for Frontend):
针对特定的前端或报表需求,创建一个专用的聚合服务。该服务通过调用多个下游微服务的API,在内存中拼接和计算数据。这种方式灵活,不破坏服务边界,适合实时性要求高、数据量不大的查询。但其性能受限于网络延迟和最慢的API,且可能给下游服务带来负载压力。
2. 事件驱动数据同步(CDC与事件溯源):
这是微服务场景下更受推崇的异步数据整合模式。核心思想是:当某个服务内的数据状态发生变化时,它并不直接暴露数据库,而是发布一个“领域事件”(如OrderCreated、InventoryUpdated)。
- 变更数据捕获(CDC):利用工具(如Debezium)直接读取数据库的binlog或事务日志,以极低的侵入性捕获数据变更,并将其作为事件流发布到消息中间件(如Kafka)。
- 专用数据处理服务作为消费者订阅这些事件流,将其转换、丰富后,写入一个为查询优化的数据仓库(如ClickHouse)、OLAP数据库(如Doris)或搜索索引(如Elasticsearch)中。这种方式实现了数据的解耦与异步复制,为统计分析提供了高性能的专用数据存储。
3. 数据湖与批处理:
对于非实时的大规模历史数据分析,可以定期(如每日)将各微服务的数据库快照或日志文件导出到中央化的数据湖(如HDFS、S3)中。然后使用批处理框架(如Spark、Flink Batch)进行ETL(抽取、转换、加载)作业,生成聚合后的统计结果。这种方式成本较低,适合离线报表和机器学习训练。
三、构建数据处理服务的关键考量
一个健壮的数据处理服务(Data Processing Service)是上述策略的核心执行者。其设计与实现需关注以下几点:
- 职责清晰:该服务应专注于数据的摄取、清洗、转换、聚合与存储,不包含核心业务逻辑。它是数据的“搬运工”和“预处理车间”。
- 容错与一致性:在处理事件流时,必须实现幂等性处理,以应对网络重试导致的消息重复。要设计检查点(Checkpoint)机制,确保数据处理进度可恢复,不丢数据。
- 可扩展性:采用流处理框架(如Apache Flink、Spark Streaming)可以天然实现水平扩展,以应对不断增长的数据流量。
- 数据模型优化:写入查询库(如OLAP引擎)的数据模型应与查询模式高度匹配,通常采用宽表、预聚合(如Sum、Count预先算好)、物化视图等方式,用空间换时间,极大提升统计查询速度。
- 元数据管理:建立数据目录,清晰记录每个数据流的来源、格式、含义、血统(Lineage)和变更历史,这是确保数据可信度的基础。
四、技术栈示例
一个典型的现代数据处理服务技术栈可能包括:
- 消息/事件流平台:Apache Kafka(数据管道中枢)
- 流处理引擎:Apache Flink(支持有状态计算、精确一次语义)
- CDC工具:Debezium(捕获数据库变更)
- 分析型数据存储:ClickHouse, Apache Doris, Amazon Redshift(用于快速即席查询)
- 数据湖存储:Amazon S3, Apache HDFS
- 任务调度与编排:Apache Airflow(管理批处理ETL任务)
- 监控与可观测性:Prometheus, Grafana(监控数据处理延迟、吞吐量)
五、结论
在微服务架构下,数据抽取与统计不再是简单的SQL查询,而是一项涉及架构模式、数据流设计与特定技术的系统工程。通过采用事件驱动的异步数据集成模式,并构建一个专注于数据处理的中台服务,我们可以在尊重微服务自治边界的高效地构建起支撑企业决策与分析的统一数据视图。关键在于平衡实时性与复杂性,选择适合业务场景的抽取策略,并利用现代化的流批一体处理框架,打造一个弹性、可靠且易于维护的数据处理管道。这不仅是技术上的升级,更是组织向数据驱动型文化迈进的重要一步。