随着企业应用规模的不断扩大,传统的单体架构逐渐难以满足快速迭代和高可用性的需求,分布式微服务架构应运而生。在这一架构中,数据处理服务作为核心组成部分,承担着数据存储、处理、流转和治理的关键职责。下面将从数据处理服务的定位、核心组件、技术选型以及最佳实践四个方面展开介绍。
一、数据处理服务的定位与重要性
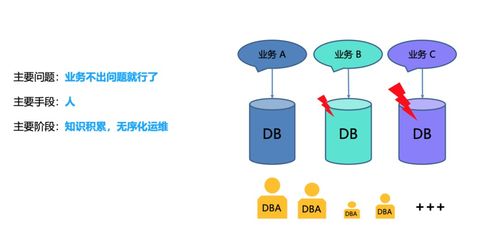
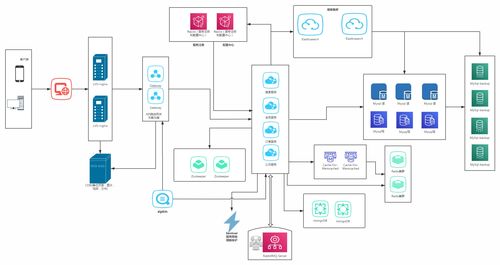
在分布式微服务业务全景图中,数据处理服务负责统一管理业务数据,确保数据在各个微服务之间的高效、安全流转。它不仅支持数据的增删改查(CRUD)操作,还涉及数据缓存、数据同步、数据聚合以及实时流处理等功能。通过数据处理服务,企业可以实现数据的高可用性、一致性和可扩展性,从而提升整体系统的稳定性和性能。
二、数据处理服务的核心组件
- 数据存储层:包括关系型数据库(如MySQL、PostgreSQL)、NoSQL数据库(如MongoDB、Redis)以及分布式文件系统(如HDFS)。选择合适的存储方案取决于业务场景,例如高频读写场景可选用Redis,复杂查询场景可选用Elasticsearch。
- 数据缓存层:通过引入缓存机制(如Redis或Memcached)减少数据库的直接访问压力,提升响应速度。缓存策略需考虑数据一致性、缓存失效和穿透问题。
- 数据同步与ETL工具:在微服务架构中,数据往往分散在不同服务中,因此需要工具(如Apache Kafka、Debezium)实现数据的实时同步和抽取、转换、加载(ETL)过程,确保数据的一致性。
- 数据处理引擎:针对不同数据处理需求,可采用批处理引擎(如Apache Spark)或流处理引擎(如Apache Flink)。例如,实时数据分析场景适合使用Flink,而大规模离线计算则依赖Spark。
- 数据治理与安全:包括数据权限管理、数据脱敏、审计日志等功能,确保数据在存储和传输过程中的安全性。工具如Apache Ranger或自定义中间件可用于实现细粒度的权限控制。
三、技术选型与实践建议
在选择数据处理服务的技术栈时,需综合考虑业务需求、团队技术储备和运维成本。以下是一些常见的技术组合:
- 对于高并发场景,可采用Redis作为缓存,MySQL作为持久化存储,并通过Kafka实现异步数据流。
- 对于大数据分析,可结合Hadoop生态(如Hive、Spark)和实时流处理工具(如Flink)。
实践建议包括:
- 服务解耦:通过事件驱动架构(如使用消息队列)减少服务间的直接依赖,提升系统弹性。
- 监控与告警:集成Prometheus、Grafana等工具,实时监控数据处理服务的性能指标,及时发现并解决瓶颈。
- 容错与重试机制:在数据同步和处理过程中引入重试策略和断路器模式,避免单点故障影响整体系统。
四、总结
数据处理服务是分布式微服务架构中的关键环节,它不仅支撑着数据的存储与流转,还直接影响系统的可靠性、性能和可维护性。通过合理设计核心组件、选择适合的技术栈,并遵循最佳实践,企业可以构建高效、稳定的数据处理体系,从而为业务创新提供坚实的数据基础。对于开发者和架构师而言,深入理解并掌握数据处理服务的全景图,是应对复杂业务挑战的必备技能。