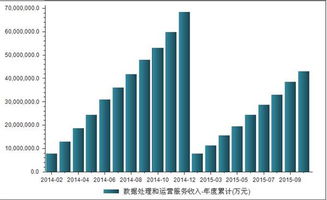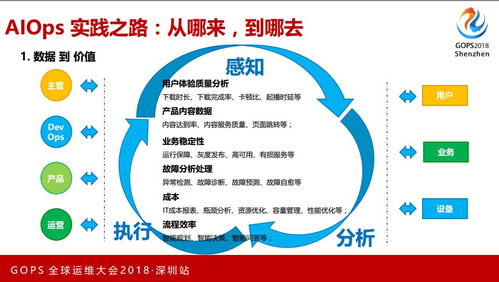
在数字化浪潮席卷全球的今天,大型互联网企业与组织正面临着前所未有的运维挑战:服务于亿级用户,管理着百TB甚至PB级别的海量数据,传统的运维模式已捉襟见肘。AIOps(智能运维)应运而生,成为破局的关键。本文将聚焦于AIOps技术栈中至关重要的一环——数据处理服务,探讨其在应对超大规模场景下的增强实践之路。
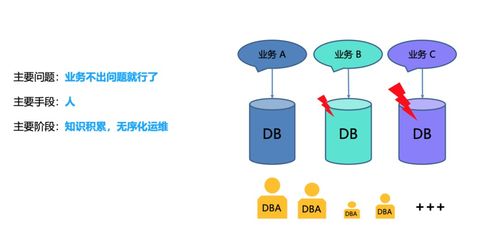
一、 基石:面对百TB数据的核心挑战
构建服务于亿级用户场景的AIOps平台,数据处理服务首先需要直面三大核心挑战:
- 数据规模与吞吐:每日产生的运维日志、指标、追踪数据轻松达到百TB级别,数据接入、实时处理与批量计算的吞吐量要求极高。
- 数据多样性:数据来源异构,包括结构化指标、非结构化日志、半结构化的调用链数据,格式繁杂,统一处理难度大。
- 时效性与准确性:故障预警要求近实时(秒级/分钟级)检测,而根因分析、容量预测等场景又需要处理高维、复杂的历史数据,对处理的延迟与结果的准确性有双重严苛要求。
二、 增强:数据处理服务的架构演进
为应对上述挑战,数据处理服务需从传统的“管道”向智能、弹性、融合的“数据中枢”演进。
1. 分层弹性架构:
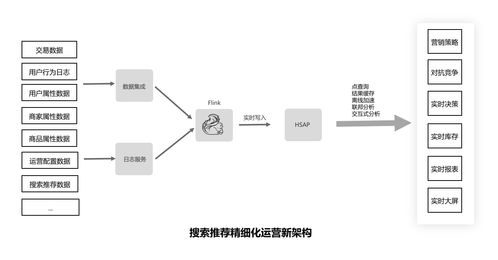
- 接入层增强:采用分布式、可水平扩展的接入网关(如基于Apache Flume, Kafka Connect的定制化Agent),支持多协议、多数据源,并具备边缘预处理能力(如格式规整、脏数据过滤),减轻核心链路压力。
- 实时处理层增强:核心是引入流批一体处理引擎(如Apache Flink)。它不仅能以极低延迟处理实时数据流进行异常检测,还能无缝衔接历史数据,进行时间窗口内的复杂事件处理(CEP)和状态计算,为实时决策提供支持。
- 批量计算与存储层增强:构建基于对象存储(如S3/OSS)和分布式数据湖(如Hudi, Iceberg)的廉价存储底座,配合Spark、Presto等计算引擎,处理海量历史数据的挖掘、模型训练与离线分析。实时与批处理的结果可统一写入数据湖,形成闭环。
2. 智能数据治理:
- 自动化数据建模:利用元数据管理,自动识别数据源、推断数据结构,并构建统一的运维数据模型(如将指标、日志、事件关联到统一的“服务-实例”维度下),为上层分析提供一致视角。
- 数据质量监控:在数据处理流水线中嵌入数据质量检查点,自动监测数据的完整性、及时性、一致性,并联动告警,确保输入AI模型的数据可靠。
- 生命周期智能管理:基于数据热度、访问模式及合规要求,制定策略自动执行数据的分层存储(热、温、冷)、压缩与归档,显著降低成本。
3. 算法与处理的深度融合:
- 处理流程嵌入模型:将轻量级AI模型(如流式异常检测算法、日志模式提取模型)直接嵌入数据管道。例如,在日志流经Kafka时即通过实时模型进行异常模式匹配和关键信息抽取,将结构化结果同步至下游,极大提升分析效率。
- 特征工程平台化:构建特征计算平台,将常用的运维特征(如时序指标的趋势、周期性、方差)计算封装为标准算子,供数据科学家和工程师在流批任务中直接调用,加速AI应用落地。
三、 实践:关键场景的技术落地
- 海量日志实时解析与索引:结合流处理引擎与自然语言处理(NLP)模型,对非结构化日志进行实时聚类、模式学习和关键信息提取,生成结构化事件,并索引到高性能存储(如Elasticsearch),使百TB日志的查询与关联分析从“不可能”变为“秒级响应”。
- 多维指标异常检测:面对数十亿维度的监控指标,利用流处理框架实时计算指标的统计特征,并集成多种轻量级无监督算法(如S-H-ESD, 移动平均)进行并行检测。将实时流与历史基线(存储在数据湖中)快速对比,实现精准、可解释的异常点定位。
- 大规模追踪数据关联分析:处理分布式调用链产生的海量Span数据,通过增强的流处理服务,实时构建完整的调用树,计算服务依赖拓扑,并关联对应的性能指标和错误日志,快速定位跨服务、跨数据中心的性能瓶颈与故障根源。
四、 未来展望
亿级用户百TB数据场景下的AIOps数据处理服务,其增强之路远未停止。未来将向着更自动化(如基于强化学习的流水线自调优)、更云原生(深度整合K8s,实现计算资源的细粒度弹性调度)、更智能化(处理过程内置更多可解释AI模型)的方向持续演进。数据处理服务不再仅仅是后台支撑,而是驱动AIOps智能进化的核心引擎,为系统的稳定性、用户体验与业务增长提供坚实的数据动能。